728x90
반응형
머신러닝 모델에서 "데이터 전처리"는 성능을 좌우하는 중요한 과정입니다.
그 중에서도 특성 스케일링(feature scaling)과 로그 변환(log transform)은 모델 학습 효율을 높이는 데 필수적인 기법입니다.
이번 글에서는 StandardScaler, MinMaxScaler, 로그 변환에 대해 간단한 이론과 실전 코드 예제를 함께 소개합니다.
1. 왜 데이터 스케일링이 필요할까?
머신러닝 알고리즘은 숫자의 절대적인 크기에 영향을 받을 수 있습니다.
예를 들어, 거리 기반 알고리즘(k-NN, SVM), 경사 하강법 기반 알고리즘(선형 회귀, 로지스틱 회귀 등)은 특성 간의 단위 차이가 클 경우 제대로 학습되지 않습니다.
이 문제를 해결하기 위해 특성값을 일정한 범위나 분포로 조정하는 과정이 바로 스케일링입니다.
2. StandardScaler - 평균 0, 표준편차 1로 조정
$$
z = \frac{x - \mu}{\sigma}
$$
- 평균을 0으로, 표준편차를 1로 맞춤
- 데이터가 정규분포에 가까울수록 효과적
- 음수 값 포함 가능
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)3. MinMaxScaler - 0과 1 사이로 압축
$$
x' = \frac{x - x_{\min}}{x_{\max} - x_{\min}}
$$
- 가장 작은 값을 0, 가장 큰 값을 1로 맞춤
- 정규분포가 아닌 경우에도 유용
- 이상치(outlier)에 민감할 수 있음
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)4. log 변환 - 값의 분포를 줄임
로그 변환은 값의 차이를 완만하게 만들어주는 역할을 합니다.
- 지수 분포, 편향된 데이터에서 효과적
- 0 또는 음수 값은 사용 불가 →
log1p(x)사용 권장
import numpy as np
# 일반 로그
X_log = np.log(X)
# 0 포함 가능하게 log(1 + x)
X_log_safe = np.log1p(X)5. 시각적으로 비교해보자
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 예제 데이터 생성
X = np.random.exponential(scale=2, size=(100, 1))
# 변환
X_standard = StandardScaler().fit_transform(X)
X_minmax = MinMaxScaler().fit_transform(X)
X_log = np.log1p(X)
# 시각화
fig, axs = plt.subplots(1, 4, figsize=(16, 4))
axs[0].hist(X, bins=20, color='gray'); axs[0].set_title("원본")
axs[1].hist(X_standard, bins=20, color='skyblue'); axs[1].set_title("StandardScaler")
axs[2].hist(X_minmax, bins=20, color='lightgreen'); axs[2].set_title("MinMaxScaler")
axs[3].hist(X_log, bins=20, color='salmon'); axs[3].set_title("log1p 변환")
plt.tight_layout()
plt.show()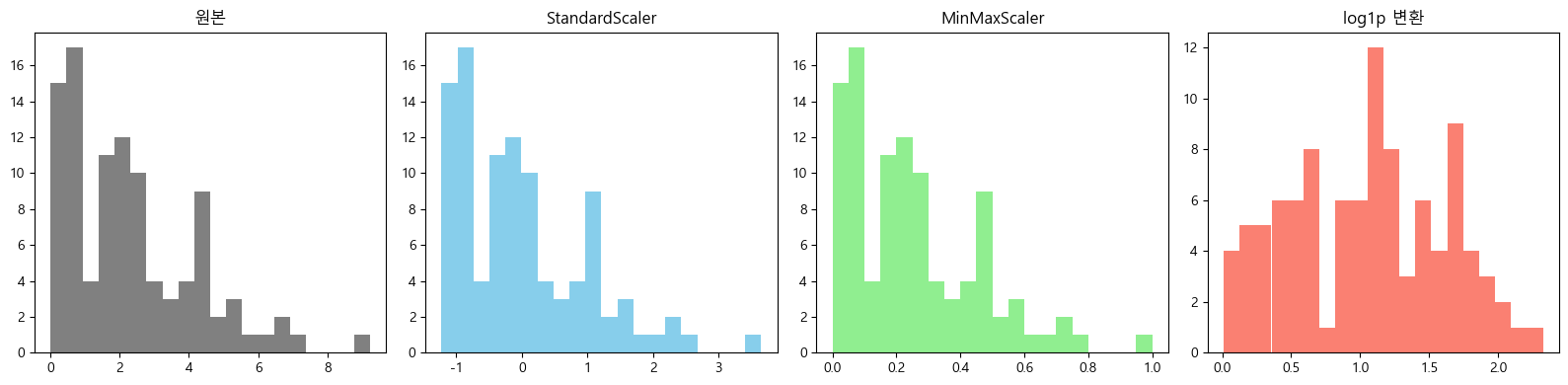
6. 언제 어떤 스케일러를 사용할까?
| 상황 | 추천 기법 |
|---|---|
| 정규분포 또는 경사 하강법 기반 모델 사용 | StandardScaler |
| 이상치가 없고, 값이 양수 | MinMaxScaler |
| 값의 분포가 한쪽에 몰려 있음 | log 변환 |
마무리
데이터를 모델에 그대로 넣는 것보다, 스케일링과 로그 변환을 거친 데이터는 훨씬 더 빠르고 안정적인 학습 결과를 보여줍니다.
728x90
반응형
'AI > Machine Learning' 카테고리의 다른 글
| 원핫 인코딩(One-Hot Encoding) (1) | 2025.04.13 |
|---|---|
| 머신러닝에서의 정규화(Regularization) (0) | 2025.04.09 |
| 로그(log)와 지수(exp)의 관계 (1) | 2025.04.08 |
| 선형 회귀 모델의 데이터 변환 (0) | 2025.04.07 |
| Bias-Variance Trade-off in python (0) | 2025.04.07 |



